
Neural Game Emulation
Close your eyes and imagine playing your favorite video game. Easy, right? Your brain has internalized the rules and graphics so well that your imagination is almost as good as playing the real thing. Your brain is essentially acting as an emulator, just at a much higher level of abstraction than a conventional software emulator.
I recently had a strange question pop into my mind. Could I train an AI to emulate video games? After a few weekends of tinkering, I discovered that the answer is “sort of, but not really.” I attempted to train a neural network to emulate the Atari game Pong, and… well, see for yourself:
At least the results are interesting to watch. I call my useless invention Dream Pong. In this post, I’ll explain what I tried and why it doesn’t work.
How Dream Pong Works
Others have tried emulating games with deep learning. One group tried to predict the next game frame from previous frames. My experiment is similar but is based on RAM, not images.
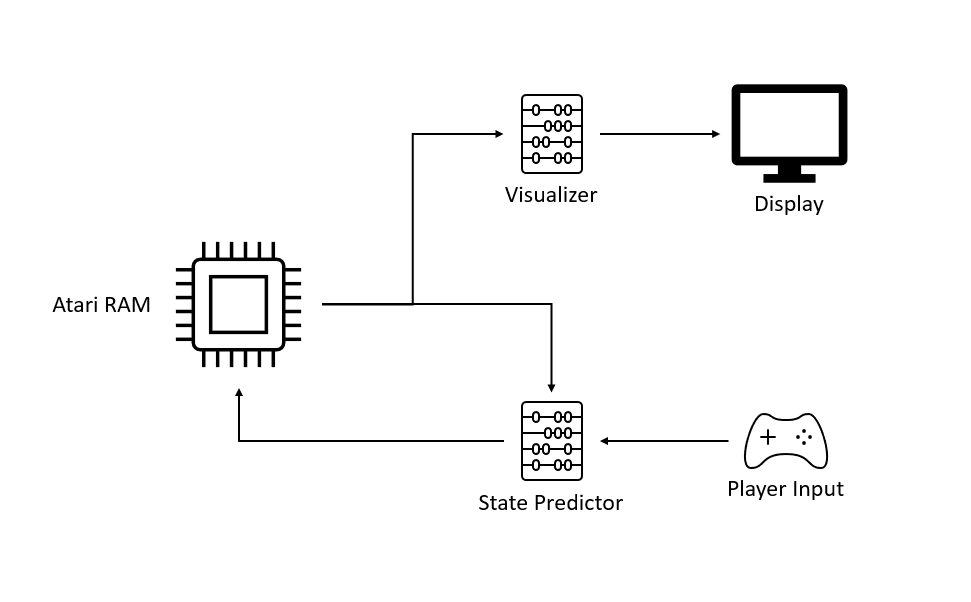
Dream Pong consists of two neural networks: the state predictor and the visualizer.
The state predictor’s job is to emulate the game by taking the current game state (stored in the Atari’s 128 bytes of RAM) and predicting the next state based on the player’s input.
The visualizer takes the current game state and generates a screenshot of the game in that state. Pretty straightforward design, but the tricky part is getting these two networks to produce anything useful.
Dataset Generation
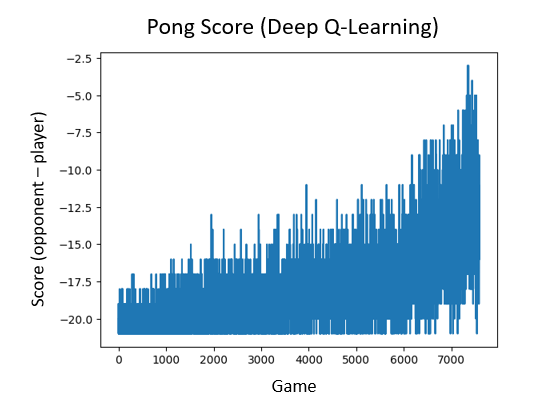
I created a dataset by recording 250 games of Pong played by a custom AI agent. I trained the AI to play Pong based on the game state stored in RAM, using the original Deep Q-Learning algorithm. After training overnight on my laptop (10 million steps, 7 thousand games), it could put up a good fight but never actually won. Good enough for me.
I then recorded my AI agent playing 250 games of Pong, saving the game screen, the RAM state, and the player’s action at each time step. About a gigabyte of data altogether.
After creating the dataset, I got to work training the state predictor and the visualizer.
The State Predictor
The state predictor was difficult to train. It achieved better results by predicting the difference between the current state and the next state, rather than by predicting the next state directly.
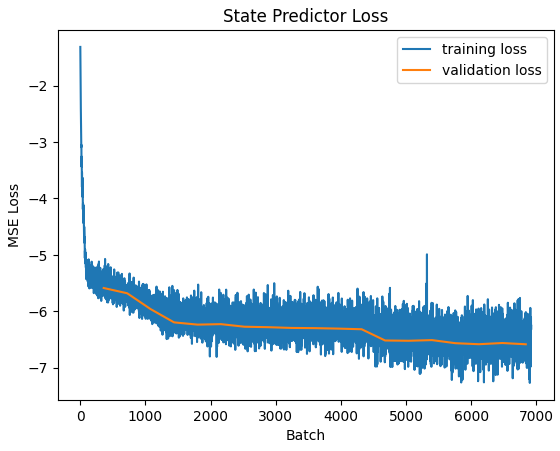
While it gets remarkably accurate, it’s still not accurate enough to simulate the game realistically.
Sadly, this makes sense because neural networks are universal function approximators. Even the tiniest bit of inaccuracy in a CPU can throw off the entire system, and it seems dubious that a neural network (of reasonable size) could approximate CPU logic without some degree of error.
My best result (twelve fully connected layers with hidden size 128) achieves a mean squared error of 0.00138, and even that isn’t enough to generate realistic results. But it is good enough to keep the simulation semi-stable for a few seconds. Sort of.
The Visualizer
The state predictor was kind of a bust. But what about the visualizer? Surprisingly, it was equally hard to train. I assumed that mapping between RAM and graphics would be simple, but alas, nothing about the Atari is as simple as it seems.
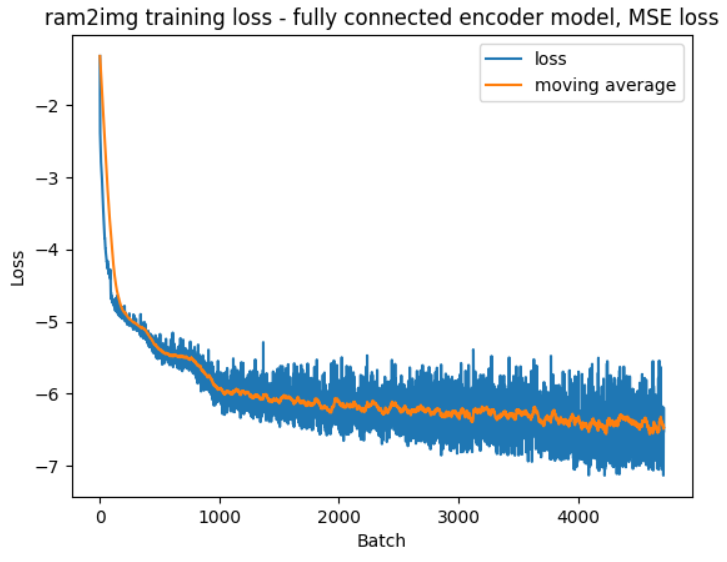
The visualizer is based on the traditional autoencoder architecture, but I modified the encoder to be fully connected instead of convolutional because it produced better results.
The visualizer takes in the 128-byte RAM input and generates a 160×210 image, which is the same resolution outputted by OpenAI’s gym environment. At first I directly outputted 160×210 pixels, but this was unnecessary since Pong visuals are blocky. To speed up training, I instead outputted a 40×52 image and upscaled it, which produced good enough results while training 4× faster.
Several quirks of Pong and the Atari 2600 make visualization a difficult problem. For example, in Pong, the smallest parts of the image are also the most important; the ball is only 2×4 pixels, so the neural net can completely ignore it and still achieve high accuracy. Sadly, the ball proved to be almost impossible for the visualizer to predict regardless of network size or training time.
I suspect the ball prediction problem is unsolvable due to a quirk in the Atari 2600 architecture. This console uses RAM in a different way from modern computers. Some claim the Atari 2600’s RAM does not capture the entire game state and that the ball’s position and velocity may be stored in external registers, not RAM. Truly a sad day for me.
But besides the ball, the visualizer works well enough to use!

I experimented with many different architectures and loss functions, but nothing improved the results significantly. The next section will expand on that, but I recommend scrolling past it unless you are really interested in loss functions for some reason.
Visualizer Loss Functions
The non-technical reader should skip to the next section.
Due to the ball prediction problem explained above, I experimented with many different loss functions with the goal of focusing the network on the most important parts of the image, namely the ball, paddles, and scoreboard.
I started with MSE (mean squared error) loss, which worked decently well. It struggled on the details but was usable.
But I wanted something even better. So I implemented a custom perceptual loss function. Both the real and generated screenshots were passed through the first few layers of a pretrained image classifier (Mobilenet v3) and measured their similarity. I hoped this loss function would emphasize edges and shapes more than simple MSE loss, but it didn’t fare much better in practice.
For my next attempt, I designed a new loss function that I call local variance attention. This function is based on MSE loss, but the resulting values are multiplied by the local variance of each pixel (i.e., how different each pixel is from its neighbors). This increases the loss of the parts of the image that are most visually interesting, like the edges of the paddles, ball, and numbers.
I hoped this technique would push the optimizer toward local minimums that were better at producing images of the ball and paddles. The mid-training outputs were fascinating. Notice how the algorithm is focused on areas that change the most frequently, like the paddle area.
Now we know the most common ball trajectories, I guess. But did attention actually improve results? Not really. It mostly just resulted in a noisier training process.
Although it wasn’t useful here, I think this local variance attention could be useful on other problems. I’m especially proud of inventing a machine learning technique that has “attention” in the name.
After this experiment, I learned that similar attention-based algorithms have been used elsewhere. One paper called it uncertainty-driven loss.
I also experimented with cross entropy loss, which is used classifiers instead of regressors. Pong can be treated as a classification problem since it needs only two values: fully black and fully white. Once again, the results were not very different. Since MSE loss is more broadly applicable to images, I decided to stick with it.
Genuine question: is there any real difference between using a regressive model with a threshold versus using a classifier model? Like for Pong, either one results in similar looking images. But should one theoretically perform better than the other? Are the gradients different or something? I couldn’t find much useful information online about this. If anyone knows, shoot me an email 👀
The Results
You’ve already seen the results of Dream Pong. Overall, the results are underwhelming, but not so terrible that I feel like I wasted my time. The simulator at least seems to vaguely understand the concepts of paddle movement and scoring.
I believe the root of the problem is that the Atari’s RAM does not capture the full internal state of the console. Thus, training a neural network on RAM will never reach sufficient levels of precision to emulate the game correctly.
However, since this quirk is unique to the Atari, it might be worth applying my approach (state predictor + visualizer) to video games from other consoles.
Conclusion
This whole experiment started as a whim: “What if neural networks can dream about video games?”
Even though the experiment mostly failed, it was fun to try! I’m sure someone will solve this problem eventually.
As someone who loves retro video games, I’ve often considered buying ROM-ripping devices so I can legally emulate my old GameCube and Game Boy Advance games.
But in the future, such devices will be unnecessary. We will simply instruct the AIs to memorize our games and hallucinate the graphics for us.
Until then, we’re stuck with our imagination.
if you're bored you can simply close your eyes and rotate a cow in your mind. it's free and the cops can't stop you
— three coffees and a nap guy (@AynRandy) February 1, 2021